Ground Truth First: Marktforschung als Garant der KI-Zukunftsfähigkeit
1. Einleitung: Der „perfekte Sturm“ der Insights-Industrie
Die Verunsicherung in der Branche ist wissenschaftlich untermauert: In der wegweisenden Untersuchung von Tomlinson et al. (2025), „Working with AI: Measuring the Applicability of Generative AI to Occupations“, wird das Disruptionspotential von KI erstmals nicht nur theoretisch simuliert, sondern auf Basis von über 200.000 realen Interaktionsdaten zwischen Nutzenden und KI-Systemen analysiert.
Die Ergebnisse sind deutlich: Der Beruf der Marktforscher und Marktforscherinnen gehört laut der Tomlinson-Skala zu den Top 40 der am stärksten exponierten Berufe von insgesamt 745 untersuchten Berufen.
| Rang | Beruf | Abdeckung | Abschlussrate | Umfang | Gesamt-Score |
|---|---|---|---|---|---|
| 1 | Dolmetschende und Übersetzende | 0,98 | 0,88 | 0,57 | 0,49 |
| 2 | Historikerinnen/Historiker | 0,91 | 0,85 | 0,56 | 0,48 |
| 3 | Passagierbegleitende | 0,80 | 0,88 | 0,62 | 0,47 |
| 4 | Vertriebsmitarbeitende (Dienstleistungen) | 0,84 | 0,90 | 0,57 | 0,46 |
| 5 | Schriftstellende und Autorinnen/Autoren | 0,85 | 0,84 | 0,60 | 0,45 |
| 6 | Kundendienstmitarbeitende | 0,72 | 0,90 | 0,59 | 0,44 |
| 7 | CNC-Programmierende | 0,90 | 0,87 | 0,53 | 0,44 |
| 8 | Telefonierende | 0,80 | 0,86 | 0,57 | 0,42 |
| 9 | Ticketverkaufende / Reisebüroangestellte | 0,71 | 0,90 | 0,56 | 0,41 |
| 10 | Rundfunksprechende und Radio-DJs | 0,74 | 0,84 | 0,60 | 0,41 |
| ... | ... | ... | ... | ... | ... |
| 37 | Marktforschungsanalystinnen und Marktforschungsanalysten | 0,71 | 0,90 | 0,52 | 0,35 |
Tabelle 1: Berufsbilder mit der höchsten KI-Exposition nach dem AI Applicability Score
Quelle: Tomlinson et al., 2025, S. 12
Die Studie belegt, dass die für den Marktforschungsberuf typischen Tätigkeiten wie das Sammeln von Informationen, das Strukturieren von Wissen und das Verfassen von Analysen eine extrem hohe „AI Applicability“ aufweisen und es damit eine große Überschneidung zwischen den Fähigkeiten der KI und den Anforderungen des Berufs gibt. Der AI Applicability Score von 0,35 platziert Marktforschungsanalystinnen und Marktforschungsanalysten unter den Top 5 % der am stärksten betroffenen Berufe. Interessant ist hierbei vor allem die Abschlussrate (Completion) von 0,90. Dies bedeutet, dass die KI in 90 % der untersuchten Fälle in der Lage war, die gestellte Aufgabe erfolgreich und vollständig zum Abschluss zu bringen. Auch wenn die Autorinnen und Autoren selbst beschwichtigen, dass hohe Scores nicht zwingend eine direkte Bedrohung des Arbeitsplatzes bedeuten. Die Ergebnisse sind ein klares Signal für einen bevorstehenden Wandel der Arbeitsinhalte der betreffenden Berufe und Branchen. Es steht außer Frage, dass sich die Arbeitswelt für Marktforschende, wie für viele andere Berufsfelder, ändern und einen großen Anpassungs- und Trainingsbedarf erzeugen wird. Ein Strukturwandel, der naturgemäß ein hohes Maß an Unsicherheit für viele Beschäftigte mit sich bringt. Diese technologische Transformation betrifft dabei nicht nur die Dienstleisterseite. Auch betriebliche Marktforschende in marktforschungsintensiven Branchen wie der Konsumgüter- oder Pharmaindustrie sehen sich mit einer wachsenden Zahl „agentischer“ KI-Lösungen konfrontiert, die autonom Analysen durchführen oder Agentur-Briefings bearbeiten können.
Der KI-bedingte Strukturwandel trifft darüber hinaus auf ein ohnehin geschwächtes Branchenumfeld von Marktforschungsdienstleistenden, die durch gleich mehrere übergeordnete Trends in die Defensive gedrängt werden:
- Strukturelle Budget-Shifts: Daten des Gartner CMO Survey verdeutlichen eine massive Umschichtung von Forschungsbudgets. Investitionen fließen zunehmend in MarTech-Infrastrukturen und automatisierte SaaS-Plattformen (Insourcing), während klassische Full-Service-Budgets inflationsbereinigt stagnieren oder schrumpfen.
- Markteintritt von Beratungsunternehmen: Akteure wie Accenture Song, Deloitte Digital oder McKinsey dringen aggressiv in das Insight-Segment vor. Durch die Integration von Datenkompetenz in hochpreisige Strategieberatung besetzen sie die oberste Wertschöpfungsstufe und drängen spezialisierte Institute in die „Commodity-Falle“.
- Aggressive Marktkonsolidierung und M&A-Welle: Das Streben nach Skaleneffekten hat eine beispiellose Konsolidierungswelle ausgelöst. Der Mega-Merger von NielsenIQ und GfK sowie die Übernahme des GfK-Consumer-Panel-Geschäfts durch YouGov illustrieren den Trend zur Bündelung von Ressourcen unter dem Druck von Private-Equity-Vorgaben und sinkenden Margen.
Dieses Zusammentreffen von struktureller Schwäche und KI-Disruptionsgefahr hat zu einer Neubewertung der meisten Marktforschungsunternehmungen auf dem Kapitalmarkt geführt. Betrachtet man die indexierte Kursentwicklung seit Einführung des ersten großen LLMs, Open AI´s Chat GPT, für die breite Öffentlichkeit, so haben nahezu alle größeren börsennotierte Akteurinnen und Akteure der Branche an Marktwert verloren. Im Gegensatz dazu hat der breit aufgestellte MSCI World Index hat im Vergleichszeitraum um bisher über 60% zugelegt (siehe Abbildung 1).
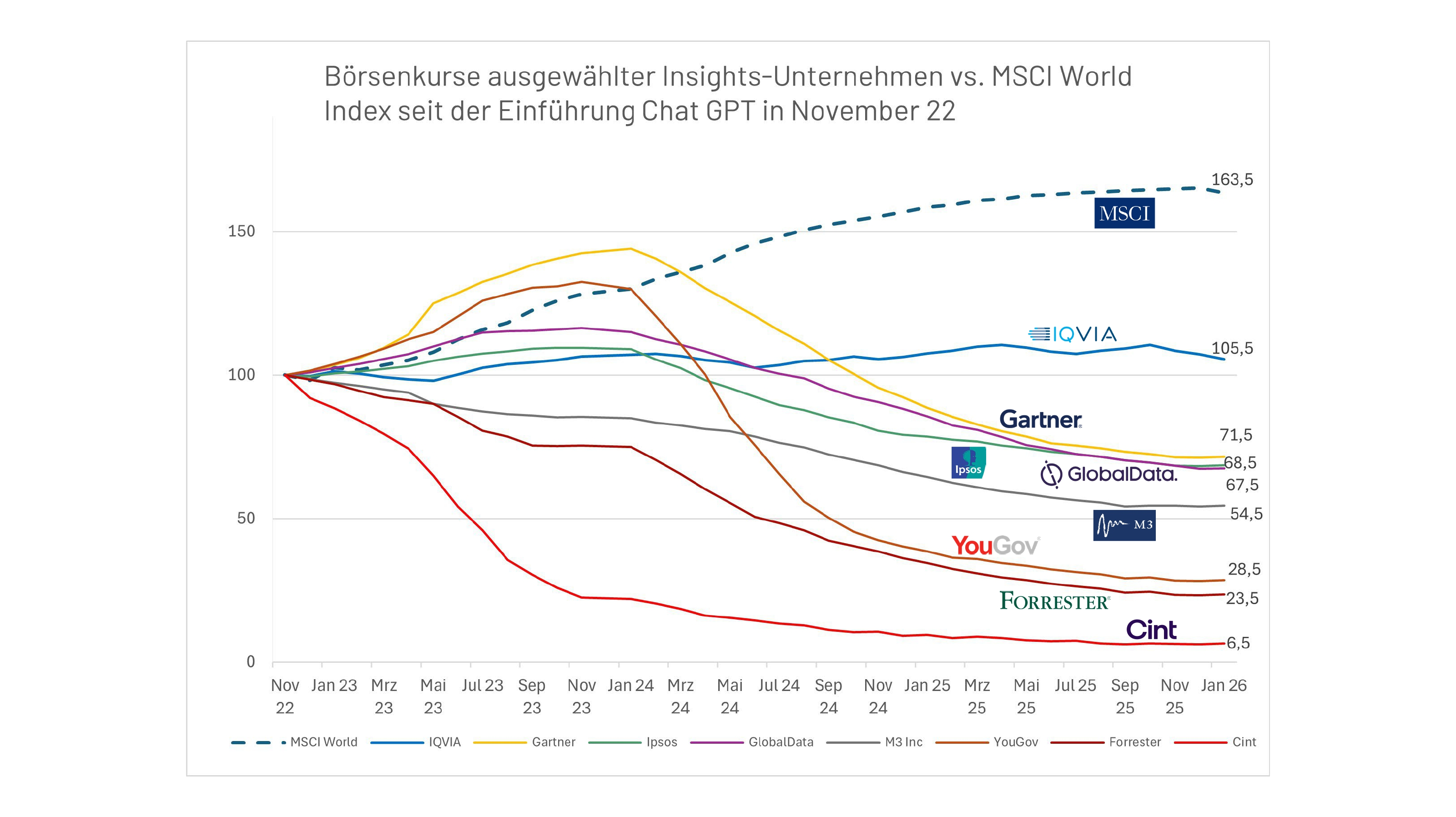
Abbildung 1: Börsenkurse ausgewählter Insights-Unternehmen vs. MSCI World Index seit November 2022
Bei genauerem Blick auf die Kursverläufe lässt sich eine zweigeteilte Entwicklung beobachten. Während einer ersten KI-Phase bis ca. Januar 2024 stiegen technologiegetriebene Research-Werte wie Gartner und YouGov sogar stärker als der MSCI World. Der Markt glaubte, dass diese Firmen die KI-Entwicklungen nutzen könnten, um ihre Effizienz und Margen deutlich zu steigern. In einer zweiten Welle ab Anfang 2024, die durch einen regelrechten KI-Investitionsboom großer Techfirmen und eine breitere KI-Adoption in verschiedenen Geschäftsfeldern gekennzeichnet ist, knicken insbesondere die Werte von YouGov, Forrester und Cint dramatisch ein. Investorinnen und Investoren realisierten, dass „einfache digitale Daten“ (Panels/Umfragen) durch synthetische Nutzende und LLM-Bots ersetzt werden könnten. Selbst Gartner, eher durch ein Consulting- als ein Marktforschungsgeschäftsmodell gekennzeichnet und anfangs als KI-Gewinner gesehen, verliert deutlich an Marktwert und es überwiegt die Sorge vor der Disruption des Geschäftsmodells. Einzig IQVIA, nach Angaben des Branchenverbands Esomar das größte Insights-Unternehmen der Welt, ist aktuell in der Lage, den Marktwert weitgehend stabil zu halten. Auch die Volatilität ist hier am geringsten, da das breite Geschäftsmodell gestützt durch die Exklusivität medizinischer Primärdaten einen starken Burggraben gegen die KI-Kommoditisierung bildet.
Schwankungen aufgrund verfehlter Quartals- oder Jahresergebnisse können natürlich kurzfristig ebenso eine Erklärung für fallende Börsenkurse sein. Es geht hier um den langfristigen Abwärtstrend einer ganzen Branche. An der Börse wird zudem die Zukunft gehandelt und nicht die partielle Problematik eines Unternehmens in der Vergangenheit. Die Durchführung solcher Kapitalmarktanalysen ist durchaus üblich.
2. Die dreifache Datenkrise der KI
Wer diese Zahlen jedoch als das Ende der Marktforschung liest, übersieht die informationstheoretische Sackgasse der KI: Large Language Models (LLMs) produzieren keine neuen Wahrheiten; sie sind statistische Spiegelbilder ihrer Trainingsdaten. Ohne stetig neue, hochwertige Trainingsdaten bzw. eine Weiterentwicklung der Trainingsdaten erlischt die Fähigkeit der Modelle, eine weiter steigende Wertschöpfung und Höherentwicklung zu generieren. Derzeit stößt die Weiterentwicklung des KI-Training an drei fundamentale Grenzen:
I. Die physische Datenmauer (Erschöpfung bestehender Daten)
Die Evolution von Large Language Models (LLMs) folgt den sogenannten Scaling Laws (Kaplan et al., 2020). Lange Zeit galt das Dogma der „Chinchilla“-Studie (Hoffmann et al., 2022), wonach die Modellleistung primär durch die massive Steigerung der Rechenleistung und der Datenmenge (D) skaliert werden kann. Eine möglichst breite Basis an originären Daten wurde so – neben der Rechenleistung – zur entscheidenden strategischen Ressource im globalen KI-Wettbewerb.
Doch diese Ära der rein quantitativen Expansion stößt an ihre physischen Grenzen. Forschungsgruppen wie Epoch AI (Villalobos et al., 2022) prognostizieren bereits für das Jahr 2026 die Erschöpfung des Bestands an qualitativ hochwertigen öffentlichen Sprachdaten. Die physische Menge an verfügbaren, menschengemachten Tokens im Netz ist endlich. Wenn das „offene Internet“ abgeerntet ist, stagniert die Leistungsfähigkeit herkömmlicher Skalierungsmethoden.
II. Das Paradoxon des sterbenden Wirts: Die Implosion von freiem Content
Während Punkt I die Limitation bzw. physische Mauer des bestehenden Archivs betrifft, beschreibt dieses Paradoxon das Versiegen zukünftigen neuen Datenflusses für die Künstliche Intelligenz. KI-Modelle zerstören durch ihren Erfolg die ökonomischen Anreize für Menschen, neuen webbasierten Content zu erstellen. Da Chatbots Antworten direkt liefern, bricht der Traffic für Herausgebende (Publisher) ein („Zero-Click“), was deren Geschäftsmodelle zerstört. Die „Wirte“ des Wissens sterben oder ziehen sich hinter Paywalls und Crawler-Blocks zurück. Die KI „verhungert“ an ihrem eigenen Erfolg, da sie die Quellen ihrer zukünftigen Intelligenz austrocknet.
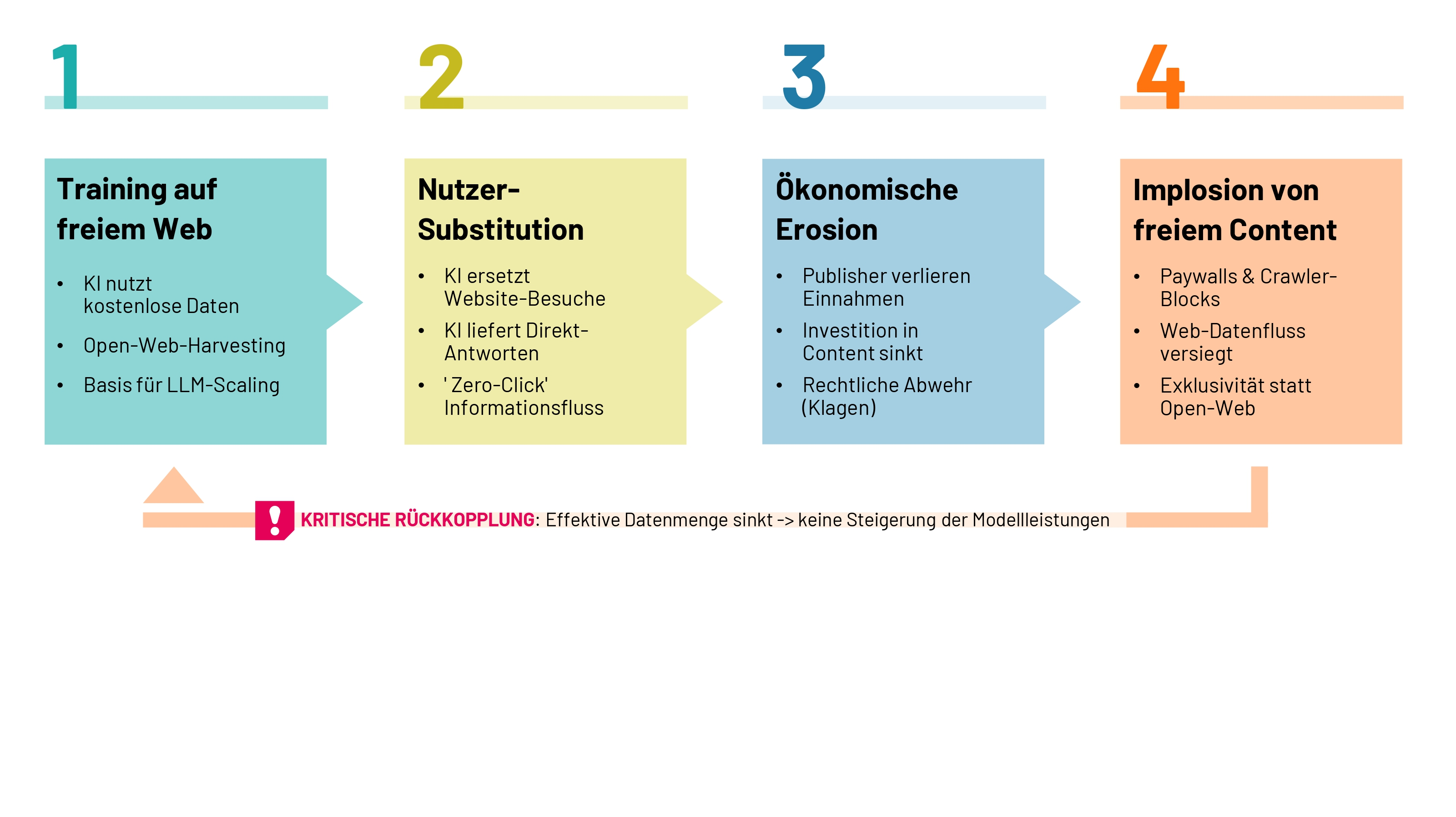
Abbildung 2: Die Folgen der stärkeren Inanspruchnahme von KI-Diensten auf die Generierung neuer freier Internetinhalte
Der Trend zeigt klar, dass freier Content immer weniger wird. Natürlich ist es schwierig genau vorherzusagen, wann es dann endgültig vorbei ist, ein paar Lockangebote oder Content für Cross-Selling werden natürlich auch in Zukunft frei angeboten werden.
Klagen wie die der New York Times gegen OpenAI (2023) zeigen, dass die Ära des „Free Lunch“ beim Datencrawling bald endgültig vorbei sein wird (Pope, 2024). Hochwertiger Content verschwindet zunehmend hinter Paywalls oder wird technisch für KI-Bots gesperrt.
III. Model Collapse: Die erzwungene Abwärtsspirale der Synthetik
Ein kritisches Phänomen bedroht die Stabilität künftiger KI-Generationen: der Model Collapse. Wie Shumailov et al. (2024) in Nature nachweisen, führen KI-Systeme, die auf synthetischen Outputs trainiert werden, unweigerlich zu einer Degeneration der Modellintelligenz.
Warum werden Modelle auf eigenen Outputs trainiert? Es gibt drei treibende Gründe, die einer „algorithmische Inzucht“ von KI-Modellen aktuell Vorschub leisten:
- Content-Implosion: Da menschliche Daten im Web versiegen, greifen Entwickelnde aus Not auf synthetische Daten zurück, um die notwendigen Volumina für das Training zu erreichen (siehe Punkt II). Verschärft wird dieser Mangel durch die „Synthetisierung der Quelle“: Laut NewsGuard (2025) fluten bereits über 2.000 rein KI-generierte Nachrichtenportale (UAINS) das Web mit algorithmischen Inhalten. Darüber hinaus inkludieren auch etablierte Nachrichtenseiten, Social-Media-Plattformen und Content-Erstellende in stetig wachsendem Maße KI-generierte Inhalte – zumindest teilweise –, was die Trennschärfe zwischen authentischer Information und synthetischem Rauschen zunehmend auflöst und die verbleibenden Primärquellen des offenen Internets kontaminiert.
- Ökonomische Effizienz: Die Erzeugung synthetischer Daten ist um Größenordnungen billiger und schneller als die Rekrutierung und Befragung echter Menschen oder das manuelle Labeling.
- Reinforcement Learning (RLHF): Entwickelnde versuchen oft, ein „starkes“ Modell zu nutzen, um die Antworten eines „schwächeren“ Modells zu korrigieren oder zu generieren.
Dieser Prozess des verstärkten Trainings auf synthetischen Daten führt jedoch dazu, dass das Modell seine Verbindung zur Realität verliert, Nuancen an den Rändern der Datenverteilung vergisst und zu einem generalisierten Durchschnitt konvergiert. Illustrativ lässt sich dies wie die „Fotokopie einer Fotokopie“ beschreiben: Mit jeder Generation gehen Nuancen, Randfälle und seltene Wahrheiten verloren. Das Modell füttert sich mit seinen eigenen Fehlern und Wahrscheinlichkeiten, und der Datenraum konvergiert zu einem trivialen Durchschnitt.
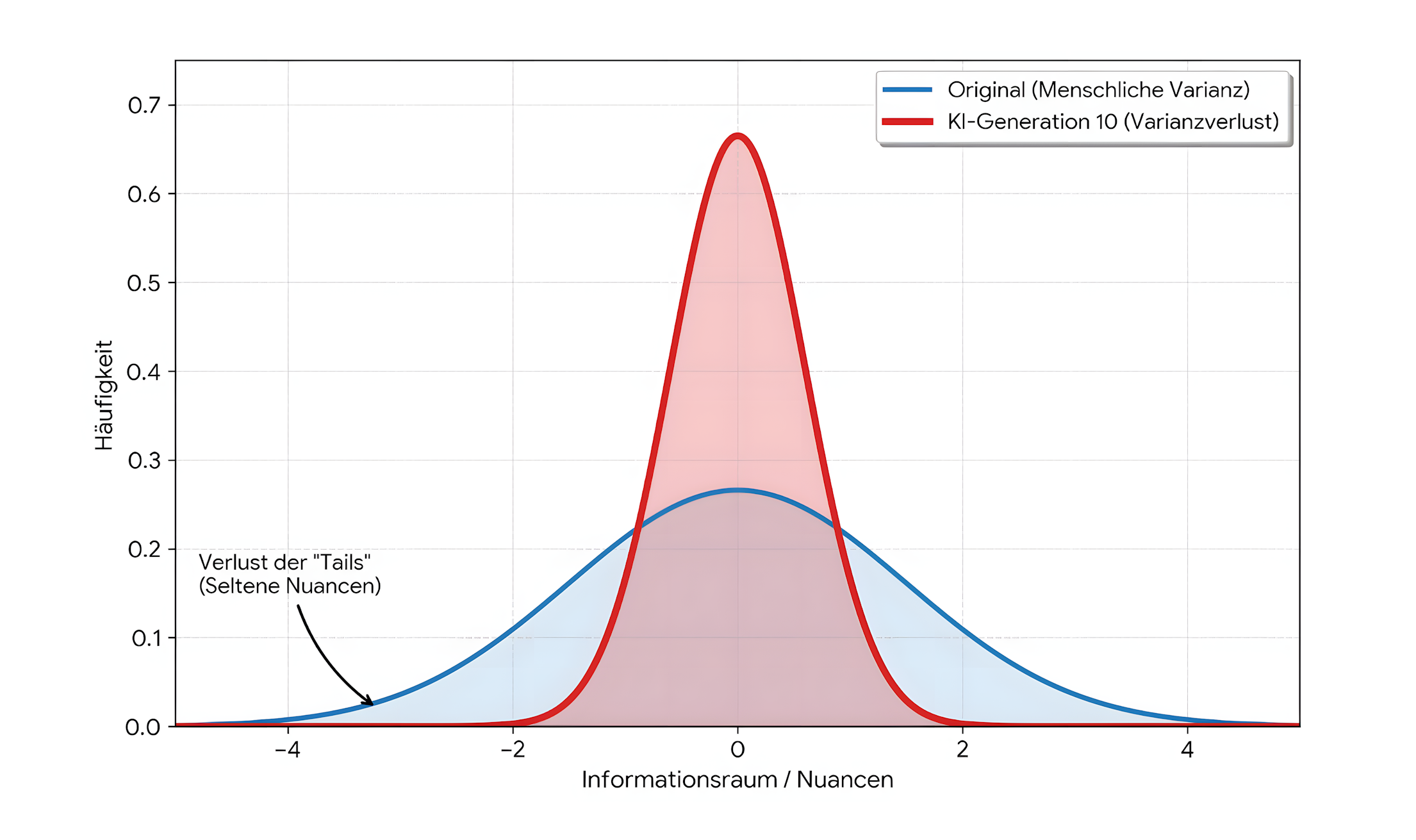
Abbildung 3: Varianzverlust durch Training auf synthetischen Daten
Diese Darstellung illustriert das statistische Kernproblem des Model Collapse: Bei einer zunehmenden Abhängigkeit von synthetischen Trainingsdaten konzentrieren sich KI-Modelle verstärkt auf die wahrscheinlichsten Muster ihrer eigenen vorangegangenen Outputs. Dieser Prozess der „algorithmischen Inzucht“ führt dazu, dass das System die essenziellen Randbereiche – die sogenannten „Tails“ der Datenverteilung – systematisch und immer weiter vernachlässigt.
Dass die Gefahr des Model Collapse keine rein theoretische ist, legen Berichte über messbare Leistungsdegradierungen bei führenden Modellen wie GPT-4 nahe, deren zeitweise abnehmende Qualität bei komplexen Aufgabenstellungen – der sogenannte „Modell-Drift“ – zunehmend als praktisches Warnsignal für die destabilisierenden Effekte rekursiven Trainings gewertet werden kann (Chen et al., 2023).
Eine weitere Manifestation der statistischen Verengung zeigt sich in der sogenannten ‚AI Slop‘-Problematik (Willison 2024). Nutzende und Unternehmen berichten zunehmend von einer qualitativen Nivellierung der Kommunikation. Ein markantes Beispiel ist das ‚Delve-Phänomen‘: Analysen zeigen, dass spezifische Buzzwords (wie delve, boast oder meticulous) seit 2023 überproportional zunehmen (Liang et al. 2024, Yakura et al. 2024). Diese sprachliche Monokultur ist ein direktes Symptom für die Gefahren eines Model Collapse: Anstatt die volle Varianz menschlichen Ausdrucks abzubilden, kollabiert der Output auf einen schmalen Korridor statistisch überrepräsentierter, aber semantisch entleerter Floskeln.
3. Marktforschung als strategische Antwort
Betrachtet man all diese kritischen Entwicklungen rund um die Verfügbarkeit von KI-Trainingsdaten, so wird schnell ersichtlich, dass die Marktforschungsindustrie einzigartig positioniert ist, um diese Krisen aufzulösen. Marktforschungsunternehmen besitzen das know-how und die Infrastruktur, um die dringend benötigte exogene Varianz und methodische Validität für KI-Modelle der nächsten Generation zu liefern:
- Methodische Qualität statt Datenmenge: Subramanyam et al. (2025) belegen, dass die effektive Datenmenge (Deff) das Produkt aus Quantität (D) und Qualität (Q) ist. Wenn Marktforschung durch methodische Exzellenz den Faktor Q steigert, erhöht dies die Effizienz des KI-Trainings massiv. Ein sorgfältig erhobener Primärdatensatz von einer Million Umfrage-Tokens kann für das Fine-Tuning wertvoller sein als zehn Milliarden verrauschte Web-Tokens. Der Fokus auf qualitativere Trainingsdaten kann damit zu einer aussichtsreichen Strategie im Wettbewerb um das beste KI-Modell vor dem Hintergrund erschöpfter frei verfügbarer Trainingsdaten werden.
- Exklusivität als „Data Moat“: Analog zu Googles exklusivem Zugriff auf Google Books oder YouTube-Transkripte wird es für Tech-Giganten ökonomisch attraktiver, Marktforschungsinstitute mit der Erhebung exklusiver Primärdaten zu beauftragen, statt rechtlich riskante Web-Daten zu nutzen. Durch die Erosion möglicher neuer freier Webinhalte wird die Auftragsforschung und dezidierte Erhebung neuer Trainingsdaten ab einem gewissen Punkt alternativlos, um führende KI-Modelle aktuell zu halten.
- Schutz vor Model Collapse: Primärforschung und neu erhobene Daten injizieren menschliche „Ground Truth“ in das System und sind damit das wichtige Korrektiv, das den algorithmischen Verfall künftiger KI-Generationen verhindert
4. Fazit: Die Marktforschung als kritische KI-Zulieferindustrie
Die wesentliche These dieses Beitrags ist, dass die beschriebenen und bereits sichtbar werdenden Datennachschubprobleme des KI-Booms eine fundamentale Neupositionierung der Marktforschungsbranche zur Folge haben werden. Marktforschungsinstitute stehen vor einer Transformation von „Berichtsliefernden“ hin zu kritischen Systemzulieferern der KI-Infrastruktur und werden damit ein wesentlicher Teil der Wertschöpfungskette für LLMs und andere AI-Applikationen (siehe Abbildung 4).

Abbildung 4: Die neue Wertschöpfungskette: Marktforschung als „Ground Truth Refinery“ für KI-Anwendungen
Ein prominentes Beispiel für diese Hypothese ist die im Mai 2025 angekündigte strategische Partnerschaft zwischen Statista, Microsoft und OpenAI (Statista Press, 2025). Durch die Integration der verifizierten Statista-Datenbestände in die KI-Assistenten (Grounding) versuchen die LLM-Entwickelnde aktiv, Halluzinationen zu bekämpfen und die Verbindung zur realen Welt wiederherzustellen. Statista fungiert hier nicht mehr als reine Plattform, sondern als „Human-Validated Data Refinery“.
Auch ein erneuter Blick auf die eingangs gezeigte Kapitalmarktanalyse großer börsennotierter Insights-Unternehmen kann als erstes Indiz für die Systemrelevanz der klassischen Primärmarktforschungsindustrie gewertet werden. Ipsos, das einzige klassische Full-Service-Marktforschungsinstitut unter den gezeigten Aktien, sinkt zwar ebenfalls deutlich im Kurs seit 11/2022. Die Aktie schlägt aber die stärker digital ausgerichteten Digital- und Consulting-Player wie YouGov, Cint oder Forrester deutlich. Dies könnte als früher Beleg für die These gewertet werden, dass durch die sich abzeichnende Krise synthetischer Daten das „alte“ Handwerk der menschlichen Validierung und Datenerhebung wieder als werthaltiger (wenn auch weniger skalierbar) eingestuft wird.
Sobald die großen LLM- Anbietenden ihre Geschäftsmodelle vollständig monetarisiert haben, werden sie im puren Eigeninteresse zu den größten Kunden der Marktforschung avancieren. Sie werden Primärdaten beauftragen – nicht für Endkundinnen und Endkunden, sondern um die „Gesundheit“ und Validität ihrer eigenen Basismodelle sicherzustellen. Marktforschung ist kein Opfer der KI-Revolution – sie ist deren unverzichtbares Fundament. In einem digitalen Ökosystem, das zunehmend durch synthetische Inhalte verwässert wird und vom „Model Collapse“ bedroht ist, steigen methodisch valide Primärdaten zur systemkritischen Ressource auf.
Für Marktforschungsunternehmen ergibt sich aus dieser veränderten Logik jedoch auch die Notwendigkeit, ihre Geschäftsmodelle stärker auf die veränderten Realitäten anzupassen und z.B. stärker ein Daten-Lizenzierungsmodell zu verfolgen. Institute könnten beispielsweise den Zugriff auf ihre Panel-APIs für Retrieval-Augmented Generation (RAG)-Systeme lizenzieren, damit KIs in Echtzeit „echte“ Konsumentenstimmen abrufen können und um „Human-in-the-loop“-Validierungen für KI-Systeme sicherzustellen.
Ja, weniger wertschöpfungstiefe Teilaufgaben wie das bloße Zusammenfassen von Daten werden wegfallen. Doch der Kern des Martkforschungsberufs – das methodische Design der „Wirklichkeits-Erfassung“ und die Bereitstellung verifizierter menschlicher Evidenz – steigt zu einem der wertvollsten Rohstoffe des 21. Jahrhunderts auf. Trotz der Entwicklung leistungsfähigerer agentischer KI-Systeme gewinnen Marktforschende auf Instituts- und Unternehmensseite dabei massiv an strategischer Relevanz. Sie fungieren als unverzichtbare Navigierende, die autonome Prozesse steuern und deren Ergebnisse durch kritisches Grounding sowie Validitätschecks strategisch absichern. Marktforschung ist kein Opfer der KI-Revolution; sie ist deren unverzichtbares Fundament und der Garant für die Zukunftsfähigkeit künstlicher Intelligenz. Marktforschende der Zukunft ist kein Berichtschreiber, sondern der Hüter der Realität in einer zunehmend synthetischen Welt.
Literatur:
- Chen, L., Zaharia, M., & Zou, J. (2023). How is ChatGPT’s behavior changing over time? arXiv:2307.09009
- Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla). DeepMind Research.
- Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2024). Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews. arXiv preprint arXiv:2403.07183. https://doi.org/10.48550/arXiv.2403.07183
- NewsGuard (2025). Tracking AI-enabled Misinformation: 2,089 Undisclosed AI-Generated News Websites (and Counting), NewsGuard AI Tracking Center. Abgerufen am 09.01.2026 von https://www.newsguardtech.com/special-reports/ai-tracking-center/
- Pope, A. (2024). NYT v. OpenAI: The Times’s About-Face. Harvard Law Review Blog. https://harvardlawreview.org/blog/2024/04/nyt-v-openai-the-timess-about-face/
- Shumailov, I., Shumaylov, Z., Zhao, Y. et al. (2024). AI models collapse when trained on recursively generated data. Nature 631, 755–759 (2024). https://doi.org/10.1038/s41586-024-07566-y
- Statista (2025). Statista's next big AI leap: 1M+ reliable data points now available in every popular AI assistant. Official Press Release, May 2025.
- Subramanyam, A., Chen, Y., & Grossman, R. L. (2025). Scaling Laws Revisited: Modeling the Role of Data Quality in Language Model Pretraining. arXiv preprint arXiv:2510.03313.
- Tomlinson, K., Jaffe, S., et al. (2025).Working with AI: Measuring the Applicability of Generative AI to Occupations. arXiv:2507.07935 (Revised Oct 2025).
- Villalobos, P., et al. (2022). Will we run out of data? Limits of LLM scaling based on human-generated data.
- Willison, S. (2024). Slop is the new name for unwanted AI-generated content. Simon Willison’s Weblog. https://simonwillison.net/2024/May/8/slop/
- Yakura, H., Lopez-Lopez, E., Brinkmann, L., Serna, I., Gupta, P., Soraperra, I. & Rahwan, I. (2024). Empirical evidence of Large Language Model’s influence on human spoken communication. arXiv preprint arXiv:2409.01754. https://doi.org/10.48550/arXiv.2409.01754
Dieser Beitrag erschien in gekürzter Form unter gleichem Titel in planung & analyse, Heft 03/2026, sowie am 19.03.2026 auf marktforschung.de.
Autor:in
-
 Dr. Michael RenzQuantitative Lead Healthcare & Lead Medical Devices and Diagnostics
Dr. Michael RenzQuantitative Lead Healthcare & Lead Medical Devices and Diagnostics